# HTTP 基础
# HTTP 的历史
20 世纪 60 年代,美国国防部高等研究计划署(ARPA)建立了 ARPA 网,它有四个分布在各地的节点,被认为是如今互联网的"始祖"。然后在 70 年代,基于对 ARPA 网的实践和思考,研究人员发明出了著名的 TCP/IP 协议
1989 年,任职于欧洲核子研究中心(CERN)的蒂姆·伯纳斯 - 李(Tim Berners-Lee)发表了一篇论文,提出了在互联网上构建超链接文档系统的构想。这篇论文中他确立了三项关键技术。
URI:即统一资源标识符,作为互联网上资源的唯一身份; HTML:即超文本标记语言,描述超文本文档; HTTP:即超文本传输协议,用来传输超文本
基于它们,就可以把超文本系统完美地运行在互联网上,让各地的人们能够自由地共享信息,蒂姆把这个系统称为"万维网"(World Wide Web),也就是我们现在所熟知的 Web
问:为什么会有 HTTP 的诞生? 答:简单来说是因为当时有此需求,网络诞生的目的是信息的交互,那必然需要能够支持此交互的通信方式传输协议,HTTP 变应运而生。
# HTTP 版本协议
HTTP/0.9 20 世纪 90 年代初期的互联网世界非常简陋,计算机处理能力低,存储容量小,网速很慢,还是一片"信息荒漠"。网络上绝大多数的资源都是纯文本,很多通信协议也都使用纯文本,所以 HTTP 的设计也不可避免地受到了时代的限制。这一时期的 HTTP 被定义为 0.9 版,结构比较简单,为了便于服务器和客户端处理,它也采用了纯文本格式,系统里的文档都是只读的,所以只允许用"GET"动作从服务器上获取 HTML 文档,并且在响应请求之后立即关闭连接,功能非常有限。
HTTP/1.0 1993 年,NCSA(美国国家超级计算应用中心)开发出了 Mosaic,是第一个可以图文混排的浏览器,随后又在 1995 年开发出了服务器软件 Apache,简化了 HTTP 服务器的搭建工作。同一时期,计算机多媒体技术也有了新的发展:1992 年发明了 JPEG 图像格式,1995 年发明了 MP3 音乐格式。这些新软件新技术一经推出立刻就吸引了广大网民的热情,更的多的人开始使用互联网,研究 HTTP 并提出改进意见,甚至实验性地往协议里添加各种特性,从用户需求的角度促进了 HTTP 的发展。 于是在这些已有实践的基础上,经过一系列的草案,HTTP/1.0 版本在 1996 年正式发布。
但 HTTP/1.0 并不是一个"标准",只是记录已有实践和模式的一份参考文档,不具有实际的约束力,相当于一个"备忘录"。所以 HTTP/1.0 的发布对于当时正在蓬勃发展的互联网来说并没有太大的实际意义,各方势力仍然按照自己的意图继续在市场上奋力拼杀
HTTP/1.1 1995 年,网景的 Netscape Navigator 和微软的 Internet Explorer 开始了著名的"浏览器大战",都希望在互联网上占据主导地位。大战的结果以 IE 取得胜利。在"浏览器大战"结束之后的 1999 年,HTTP/1.1 发布了 RFC 文档,编号为 2616,HTTP/1.1 是对 HTTP/1.0 的小幅度修正。但一个重要的区别是:它是一个"正式的标准",而不是一份可有可无的"参考文档"。
文本协议 主要的变更点
- 增加了 PUT、DELETE 等新的方法;
- 增加了缓存管理和控制;
- 明确了连接管理,允许持久连接;
- 允许响应数据分块(chunked),利于传输大文件;
- 强制要求 Host 头,让互联网主机托管成为可能;
HTTP/2.0 HTTP/1.1 发布之后,历经十余年的时间,HTTP 的使用也带来了一些问题,主要就是连接慢。Google 首先开发了自己的浏览器 Chrome,然后推出了新的 SPDY 协议,并在 Chrome 里应用于自家的服务器,Google 借此顺势把 SPDY 推上了标准的宝座,互联网标准化组织以 SPDY 为基础开始制定新版本的 HTTP 协议,最终在 2015 年发布了 HTTP/2,RFC 编号 7540
虽然 HTTP/2 已发布数年,也衍生出了 gRPC 等新协议,但由于 HTTP/1.1 实在是太过经典和强势,目前它的普及率还比较低,大多数网站使用的仍然还是 20 年前的 HTTP/1.1
- 二进制协议,不再是纯文本
- 一次发出多个请求,废弃 HTTP1.1 里面的管道
- 使用专用算法进行头部压缩,减少数据的传输量
- 允许服务器主动的向客户端推送数据
- 增强了安全性,"事实上"要求加密通信
HTTP/3.0 在 HTTP/2 还处于草案之时,Google 又发明了一个新的协议,叫做 QUIC。 2018 年,互联网标准化组织 IETF 提议将"HTTP over QUIC"更名为"HTTP/3"并获得批准,HTTP/3 正式进入了标准化制订阶段,也许两三年后就会正式发布,到时候我们很可能会跳过 HTTP/2 直接进入 HTTP/3
问:HTTP 协议有哪些版本? 答:HTTP 0.9/1.0/1.1/2.0/3.0
- HTTP/0.9 是个简单的文本协议,只能获取文本资源;
- HTTP/1.0 确立了大部分现在使用的技术,但它不是正式标准;
- HTTP/1.1 是目前互联网上使用最广泛的协议,功能也非常完善;
- HTTP/2 基于 Google 的 SPDY 协议,注重性能改善,但还未普及;
- HTTP/3 基于 Google 的 QUIC 协议,是将来的发展方向
# 什么是 HTTP
定义上来看,HTTP 就是超文本传输协议,也就是 HyperText Transfer Protocol
超文本 传输 协议
HTTP 是一个协议,是一个用在计算机世界里的协议。它使用计算机能够理解的语言确立了一种计算机之间交流通信的规范,以及相关的各种控制和错误处理方式。 HTTP 是一个传输协议,是一个在计算机世界里专门用来在两点之间传输数据的约定和规范。所谓的"传输",就是把一堆东西从 A 点搬到 B 点,或者从 B 点搬到 A 点,即"A<===>B",这是一个双向的过程,同时存在请求方和响应方。
所谓"文本"(Text),就表示 HTTP 传输的不是 TCP/UDP 这些底层协议里被切分的杂乱无章的二进制包(datagram),而是完整的、有意义的数据,可以被浏览器、服务器这样的上层应用程序处理。在互联网早期,"文本"只是简单的字符文字,但发展到现在,"文本"的涵义已经被大大地扩展了,图片、音频、视频、甚至是压缩包,在 HTTP 眼里都可以算做是"文本"。 所谓"超文本",就是"超越了普通文本的文本",它是文字、图片、音频和视频等的混合体,最关键的是含有"超链接",能够从一个"超文本"跳跃到另一个"超文本",形成复杂的非线性、网状的结构关系
综上:超文本传输协议 -> HTTP 是一个在计算机世界里专门在两点之间传输文字、图片、音频、视频等超文本数据的约定和规范
问:HTTP 到底是什么 答:
- HTTP 是一个用在计算机世界里的协议,它确立了一种计算机之间交流通信的规范,以及相关的各种控制和错误处理方式。
- HTTP 专门用来在两点之间传输数据,不能用于广播、寻址或路由。
- HTTP 传输的是文字、图片、音频、视频等超文本数据。
- HTTP 是构建互联网的重要基础技术,它没有实体,依赖许多其他的技术来实现,但同时许多技术也都依赖于它
超文本:
- 超出文本的内容 包括音频视频 图片
- 超链接跳转
# 一个简单的 HTTP 连接
准备:Chrome, WireShark, HTTP Server(koa2) A.Koa2
const Koa = require('koa');
const app = new Koa();
app.use(async ctx => {
ctx.body = 'Hello World';
});
app.listen(3000);
B.WireShark(osx)
- 选择 loopback: lo0
- 过滤条件
tcp.port == 3000
C.Chrome 输入http://localhost:3000/ 看到Hello World已经返回
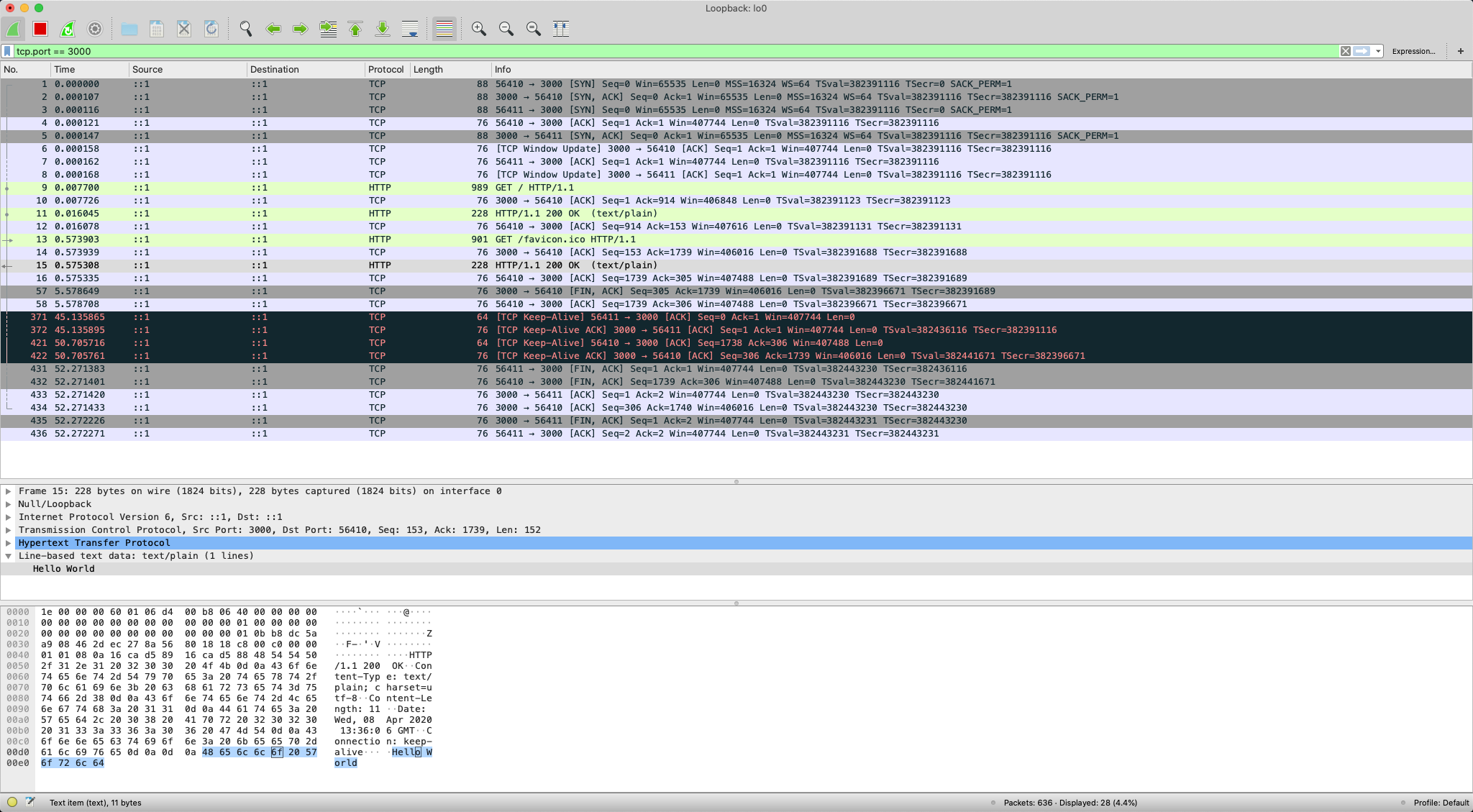
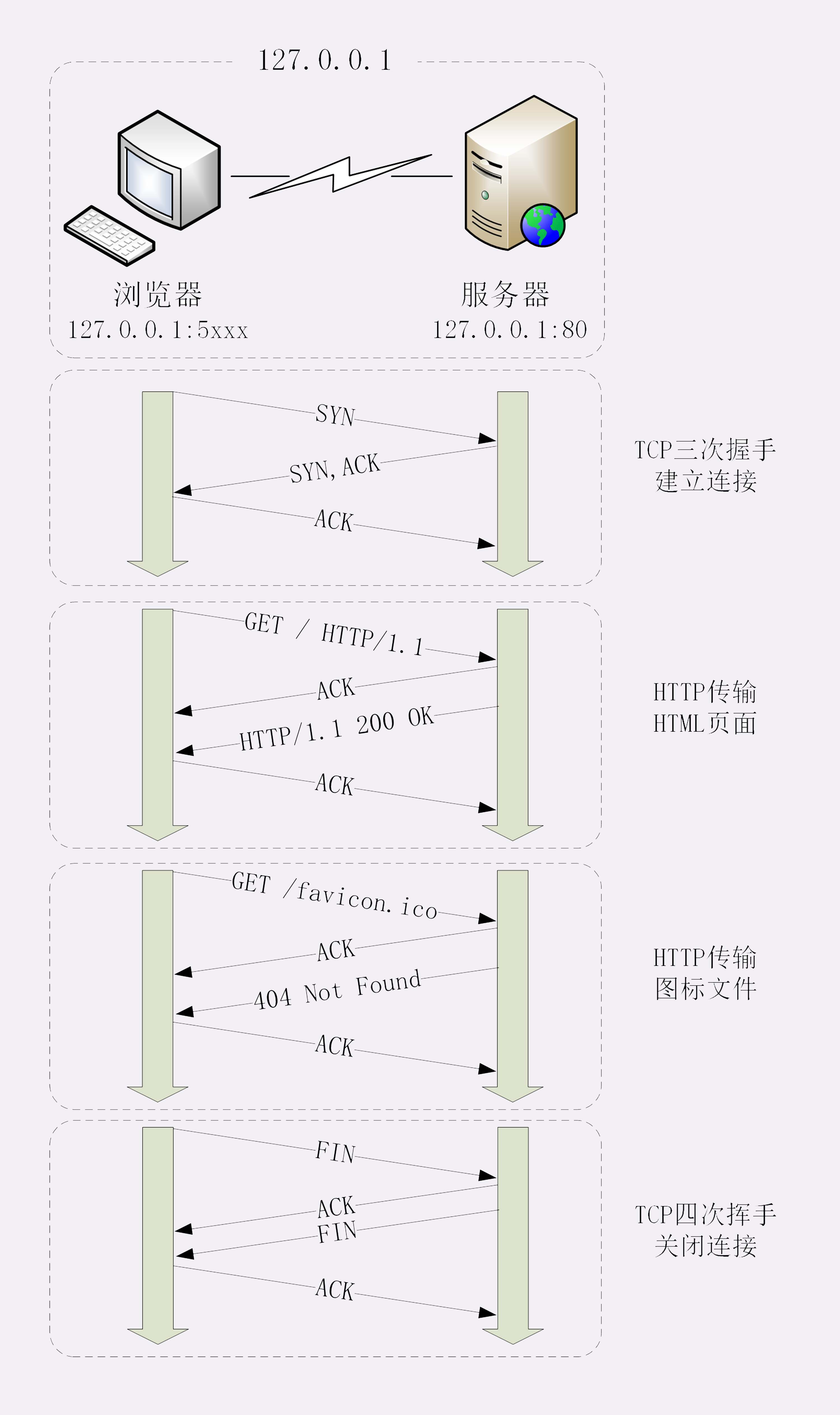
过程分析: HTTP 协议是运行在 TCP/IP 基础上的,依靠 TCP/IP 协议来实现数据的可靠传输。所以浏览器要用 HTTP 协议收发数据,首先要做的就是建立 TCP 连接:
- 地址栏里直接输入了 IP 地址"127.0.0.1",而 Web 服务器的默认端口是 80,所以浏览器就要依照 TCP 协议的规范,使用"三次握手"建立与 Web 服务器的连接
- TCP 连接建立后,根据 HTTP 协议, 发送 GET / HTTP/1.1
- 服务器收到请求,进行处理,返回 Hello World 字符串
- 浏览器解析 HTML,渲染网页
- TCP 四次挥手,关闭连接
# HTTP 报文结构
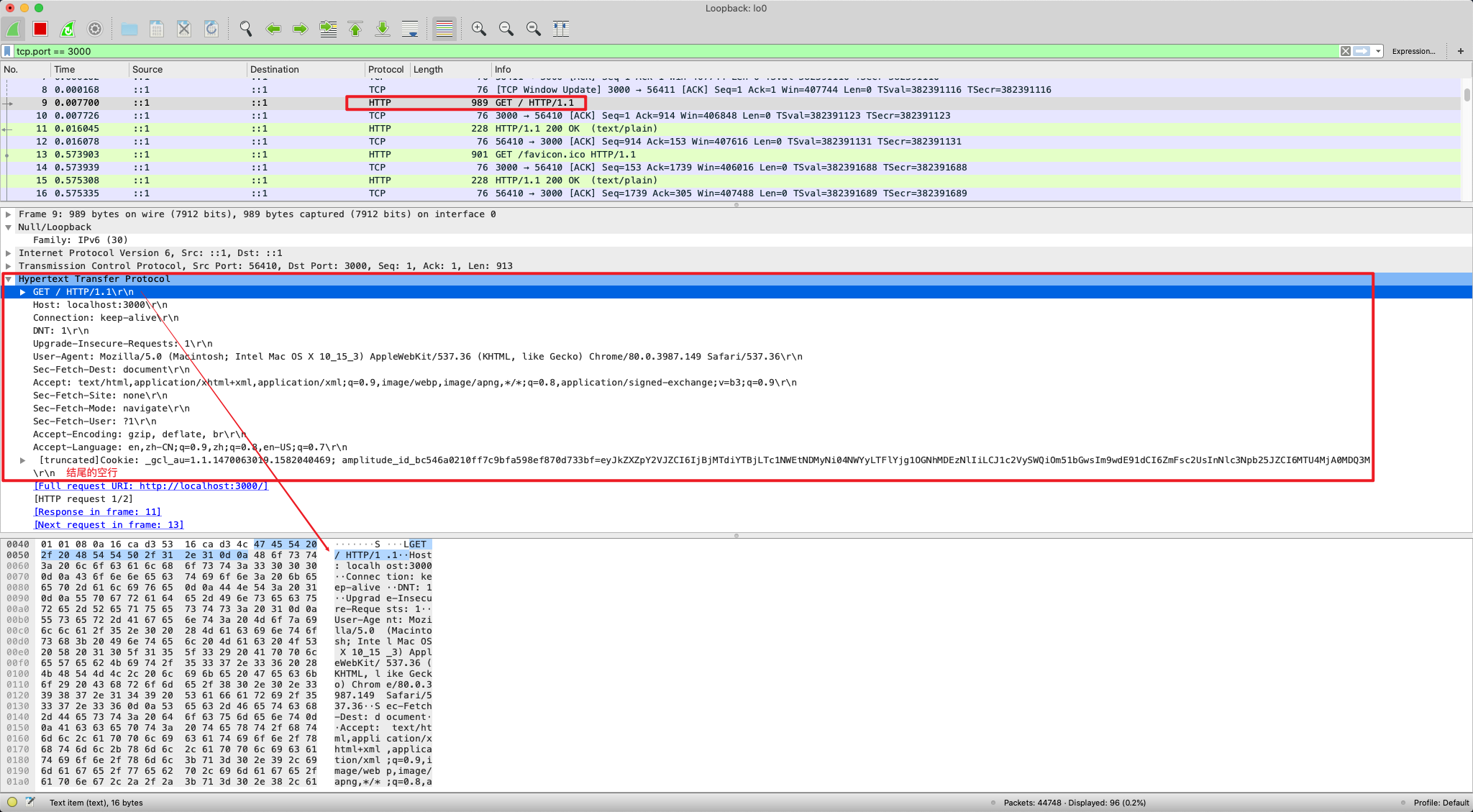
HTTP 协议也是与 TCP/UDP 类似,但是他是一个纯文本的协议,头数据都是 ASCII 码的文本,可以直观的看懂。
HTTP 协议的请求报文和响应报文的结构基本相同,由三大部分构成:
- 起始行(start line):描述请求或响应的基本信息;
- 头部字段集合(header):使用 key-value 形式更详细地说明报文;
- 消息正文(entity):实际传输的数据,它不一定是纯文本,可以是图片、视频等二进制数据。
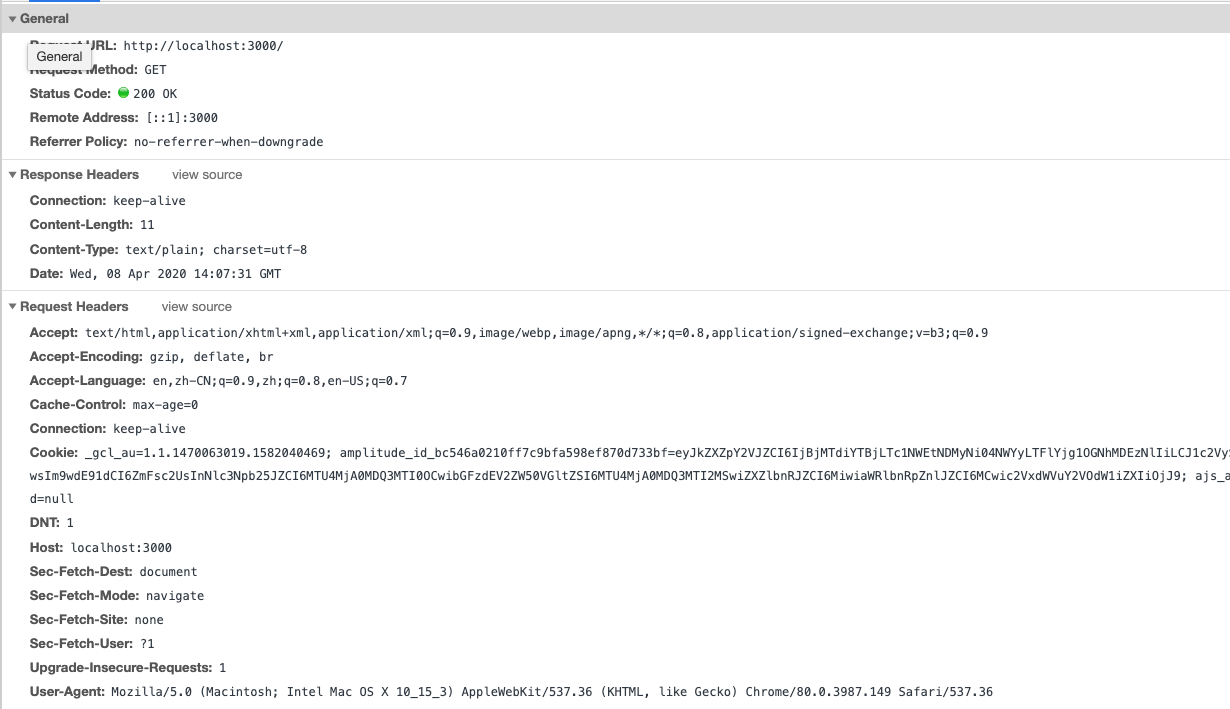
我们通常在 Chrome 浏览器上看到的是这个样子,这个已经是 chrome 浏览器做了处理,并不代表 http 报文原本的样子
# 请求报文
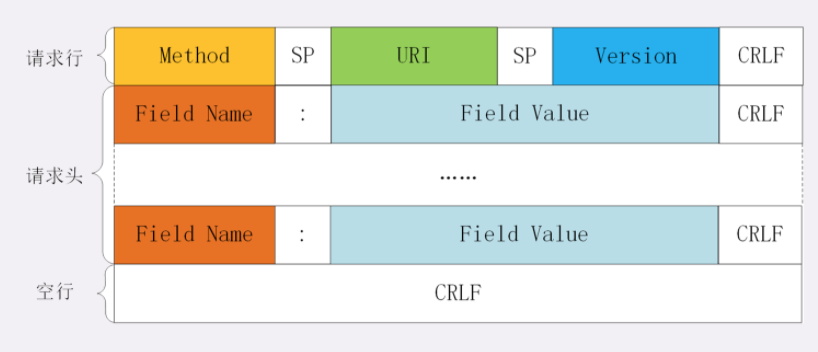
结构:
起始行:GET / HTTP/1.1
头部字段:key-value 形式的键值对 比如:Host: www.baidu.com
空行:0D0A
实体:body (可为空)
起始行和头部字段经常又合称为"请求头",消息正文又称为"实体"或者 body
HTTP 协议规定报文必须有 header,但可以没有 body,而且在 header 之后必须要有一个"空行",也就是"CRLF",十六进制的"0D0A"
# 起始行/请求行
- 请求行由三部分构成:请求方法:是一个动词,如 GET/POST,表示对资源的操作;
- 请求目标:通常是一个 URI,标记了请求方法要操作的资源;
- 版本号:表示报文使用的 HTTP 协议版本。
eg:
GET / HTTP/1.1
这三个部分通常使用空格(space)来分隔,最后要用 CRLF 换行表示结束

# 头部字段
头部字段是 key-value 的形式,key 和 value 之间用":"分隔,最后用 CRLF 换行表示字段结束。比如在"Host: 127.0.0.1"这一行里 key 就是"Host",value 就是"127.0.0.1"
eg:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate, br
Accept-Language: en,zh-CN;q=0.9,zh;q=0.8,en-US;q=0.7
Cache-Control: max-age=0
Connection: keep-alive
请求头总结
# 响应报文
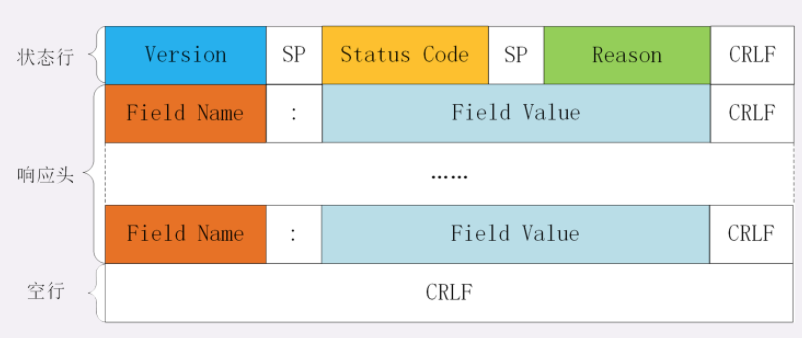
# 状态行
- 版本号:表示报文使用的 HTTP 协议版本;
- 状态码:一个三位数,用代码的形式表示处理的结果,比如 200 是成功,500 是服务器错误;
- 原因:作为数字状态码补充,是更详细的解释文字,帮助人理解原因
HTTP/1.1 200 OK
# 头部字段
和请求头类似,字段不同
Connection: keep-alive
Content-Length: 11
Content-Type: text/plain; charset=utf-8
Date: Wed, 08 Apr 2020 14:07:31 GMT
响应头总结
# HTTP 请求方法
请求方法的实际含义就是,客户端发出了一个“动作指令”,要求服务器端对 URI 定位的资源执行这个动作
目前 HTTP/1.1 规定了八种方法,单词都必须是大写的形式
GET:获取资源,可以理解为读取或者下载数据;
HEAD:获取资源的元信息;
POST:向资源提交数据,相当于写入或上传数据;
PUT:类似 POST;
DELETE:删除资源;
CONNECT:建立特殊的连接隧道;
OPTIONS:列出可对资源实行的方法;
TRACE:追踪请求 - 响应的传输路径
虽然 HTTP/1.1 里规定了八种请求方法,但它并没有限制我们只能用这八种方法。
# HTTP 状态码
RFC 标准把状态码分成了五类,用数字的第一位表示分类,而 0~99 不用,这样状态码的实际可用范围就大大缩小了,由 000~999 变成了 100~599
这五类的具体含义是:
- 1××:提示信息,表示目前是协议处理的中间状态,还需要后续的操作;
- 2××:成功,报文已经收到并被正确处理;
- 3××:重定向,资源位置发生变动,需要客户端重新发送请求;
- 4××:客户端错误,请求报文有误,服务器无法处理;
- 5××:服务器错误,服务器在处理请求时内部发生了错误。
# HTTP 的特点
- HTTP 是灵活可扩展的,可以任意添加头字段实现任意功能;
- HTTP 是可靠传输协议,基于 TCP/IP 协议“尽量”保证数据的送达;
- HTTP 是应用层协议,比 FTP、SSH 等更通用功能更多,能够传输任意数据;
- HTTP 使用了请求 - 应答模式,客户端主动发起请求,服务器被动回复请求;
- HTTP 本质上是无状态的,每个请求都是互相独立、毫无关联的,协议不要求客户端或服务器记录请求相关的信息;
# HTTP 的优点和缺点
# 优点
- 简单、灵活、易于扩展
- 应用广泛、环境成熟
- 无状态
# 缺点
- 通信使用明文(不加密),内容可能会被窃听
- 不验证通信双方的身份,因此有可能遭遇伪装
- 无法证明报文的完整性,所以有可能已遭篡改
# 声明
部分内容参考极客时间《透视 HTTP 协议-罗剑锋》的课程内容,如果想深入学习 HTTP,请移步:极客时间-透视 HTTP 协议 (opens new window)